作者: Jun Han @ 复旦大学
发表在: IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS_2022(中科院一区)
背景
5G 边缘计算基础设施应通过实施后量子密码 (PQC) 来增强抗量子攻击能力。在各种 PQC 方案中,基于错误学习 (LWE) 的格基密码 (LBC) 因其性能效率和安全性保证而备受关注。在基于 LWE 的 LBC 中,基于 Module-LWE 的方案受益于独特的多项式矩阵和向量结构,比其他方案更具优势。
工作
为了为边缘计算范式提供 Module-LWE 应用程序的高性能实现,我们提出了一种基于 RISC-V 架构矩阵扩展的领域特定处理器。
全栈异构评估平台
- TVM是一个端到端优化堆栈,它公开了图形级和操作符级优化,为不同硬件后端的深度学习工作负载提供性能可移植性。
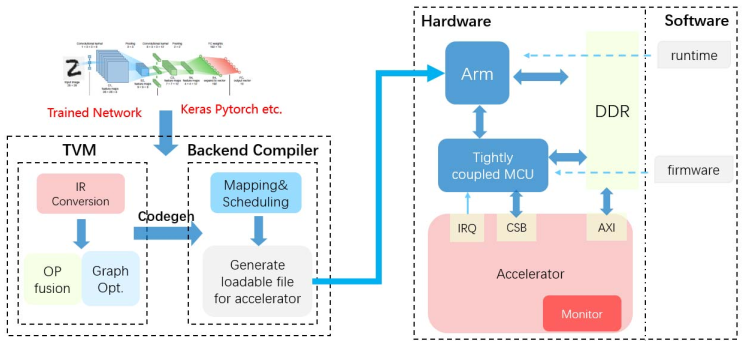
- NVDLA是一款由NVIDIA发布的开源的神经网络加速器,是一款由编译器、runtime、firmware和加速器组成的全栈加速器。
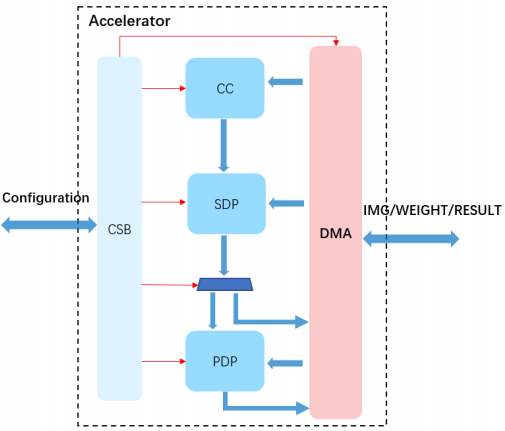
如图所示,NVDLA主要包含CC(Convolution Core),SDP(Single Point Data Processor)和PDP(Planar Data Processor)
作者的平台如下图所示:
更详细的硬件信息:
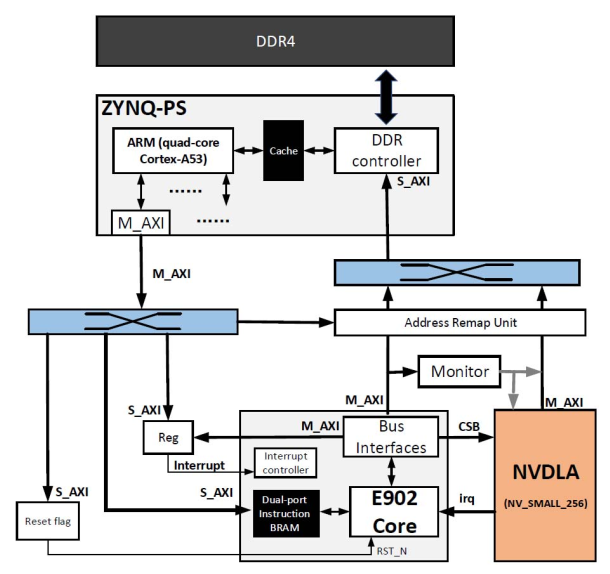
其中包含一个Monitor,用来监控 - CC、SDP、PDP的运行时间和有效计算时间。
- 加速器的有效内存访问次数和总内存访问时间
通过该评估系统,能够获得网络的以下性能指标 - Latency:整个网络计算开始到结果出来的时间
- Computation density:total network operations (FLOPs) / computation time(s)。该指标准确反映了网络在特定硬件上的适应性。对于两个参数数量大致相同的网络,根据其结构,硬件上会发生额外的内存访问操作,导致性能下降。
- DLA的内存访问时间和带宽
- 每个单元的运行时间。该指标反映了网络的计算资源消耗情况,根据该指标可以判断网络的性能瓶颈,从网络角度可以进一步优化网络超参数,提高性能;从硬件的角度来看,应该为长时间运行的部分设计更多的计算资源,下面的实验部分,我们统计了CC的运行时间,SDP和PDP。